GCPのユーザーを削除したら、AWSに置いてたshellスクリプトがAccess denied.
AWSに立てているサーバからGCPのCloudStorageにshellスクリプトでデータを飛ばしていた。shellスクリプトは他の方が書いたものなので、中身はあまりわかっていない。
ある日、
An error occurred (AccessDenied) when calling the PutObject operation: Access denied.
と言ってデータが飛んでこなくなった。ちょうどGCPアカウントの整理をして一部ユーザーを削除した直後だったので、それ関連っぽいと検討。
どうやら.awsのcredentialsに書き込むaws_access_key_idとaws_secret_access_keyが元凶らしい。
WS EC2からGCP Cloud storage、GCP GCEからAWS S3へのアップロード - 2&>1
これらはCloudStorageの「設定 > 相互運用性 > 相互運用ストレージアクセスキー」から作成するが、どうやら作成者のユーザーアカウントに紐付いているらしく、そのユーザーアカウントが消えると同時に消滅する模様。
アクセスキー、シークレットキーの発行方法を教えてください。 | クラウドストレージ
別のユーザーで作成し直して、credentialsを上書きして修正は終わり。
でもこれ、作り直したユーザーアカウントが消えるとまた消えてしまう。永続化できないんだろうか。
【2022年4月17日追記】
普通にサービスアカウントで作成できるらしい。
サービス アカウントを使用すれば、ユーザー アカウントへの依存に伴うサービス停止(たとえば、ユーザーがプロジェクトから抜けたり退社したりして、そのユーザー アカウントが無効になった場合)のリスクを軽減します。
HMAC キー | Cloud Storage | Google Cloud
GoogleAnalytics4のBigQuery連携データをユーザー単位のページ遷移に加工するクエリ
GoogleAnalytics4のrawデータから、ユーザー単位(user_pseudo_id)でページ遷移が分かるデータマートを作成する。
手順
1. UNNESTでフラット化
2. ga_session_id, page_title, page_locationを横持ち
3. 同一ページで複数のeventが発生していても最初のtimestampだけ残すように、event_date, user_pseudo_id, ga_session_id, page_title, page_location単位のQUALIFY句
#standardSQL WITH -- 1. UNNESTでフラット化 tbl AS ( SELECT DISTINCT event_date, event_timestamp, user_pseudo_id, event_params.key AS event_params_key, event_params.value.string_value AS event_params_value_string_value, event_params.value.int_value AS event_params_value_int_value FROM `hatena-ga.analytics_xxxxxxx.events_*`, UNNEST(event_params) AS event_params WHERE (event_params.key IN ("page_location", "page_title", "ga_session_id")) ) SELECT -- 2. ga_session_id, page_title, page_locationを横持ち event_date, FORMAT_TIMESTAMP("%Y-%m-%d %H:%M:%S", TIMESTAMP_TRUNC(TIMESTAMP_MICROS(event_timestamp), second), "Asia/Tokyo") AS event_timestamp_tokyo, user_pseudo_id, MAX(CASE event_params_key WHEN "ga_session_id" THEN event_params_value_int_value ELSE NULL END) AS ga_session_id, MAX(CASE event_params_key WHEN "page_title" THEN event_params_value_string_value ELSE NULL END) AS page_title, MAX(CASE event_params_key WHEN "page_location" THEN event_params_value_string_value ELSE NULL END) AS page_location, FROM tbl GROUP BY event_date, user_pseudo_id, event_timestamp QUALIFY -- 3. 同一ページで複数のeventが発生していても最初のtimestampだけ残す ROW_NUMBER() OVER (PARTITION BY event_date, user_pseudo_id, ga_session_id, page_title, page_location ORDER BY event_timestamp ASC) = 1 ORDER BY event_date, user_pseudo_id, event_timestamp
結果はこんな感じ。

GoogleAnalytics入門 with R 中編 ~BigQuery連携データについて~

GoogleAnalyticsのBigQuery連携についての紹介記事。
勉強会で発表したものを文字にした記事で、元のスライドはこちら。
Introduction_of_GoogleAnalytics_with_R - Speaker Deck
GoogleAnalyticsそのものについてはこちら。
アップデートによるBigQuery連携無償化
GUIで確認できるGoogleAnalyticsデータはすでに集計されたもので、場合によってはサンプリングがかかる。APIを利用して得られるデータも同様に集計されており、rawデータの取得するには有料版の契約が必須になっていた。
しかし、2020年10月に行われたGoogleAnalyticsのアップデートにより無償版でもBigQuery連携が可能になった。正確に言うとこれまでのUniversalAnalyticsに加えて、新版のGoogleAnalytics4というもの(プロパティと呼ばれる)が使えるようになった。

BigQuery連携手順
連携の設定はGUI上でできる。GoogleAnalytics4のプロパティでしかできないので注意。
連携の頻度はdailyとstreamingから選択する。両方、というのも可能。
Googleアナリティクス4のデータをBigQuery出力する | marketechlabo

連携の設定が終わって、翌日からBigQueryにデータセットとテーブルが作成される。
データセットは「analytics_xxxx」という名称で「xxxx」部分にIDのようなものが入る。このデータセット配下に日次でテーブルが追加されていく。テーブル名は「events_YYYYMMDD」の形。いわゆるシャーディングになる。streamingの場合はこれらとは別に「events_intraday_YYYYMMDD」というテーブルができる。
shardingとpartitioningの違いは?【分散データベース】 - CTOの日記

連携データの内容
連携されたデータはネストされた状態。
BigQuery Export のスキーマ - Firebase ヘルプ

列がたくさんあるが「いつ」「何をした」「誰が」の3つを中心に見ると掴みやすい。
いつ
・event_timestamp……ミリ秒単位のUTC。日付や時刻は「UTC ミリ秒値で表される現在時刻」で扱うのが便利
・event_date……event_timestampをGoogleAnalyticsで登録されたタイムゾーンに合わせてYYYYMMDDの形に変換されたもの。
誰が
・user_pseudo_id……ユーザーの仮のID。Webサイトであればcookie単位で発行される。
何をした
・event_name……ユーザーが何をしたのか。page_view、scroll、clickなど。
・event_params……行動の詳細。その行動が起こったページ、行動が起こったセッションのIDなど。

eventの構成
ユーザーが「何をしたのか」を表す列には「event」という名称がついている。これはGoogleAnalytics4が計測をしている最小単位で、ユーザーの1つ1つの行動を指す。
「いつ」「誰が」と並んで重要な列だが、ネストしているため扱いづらい。
イメージとしてはこんな感じ。

event_nameはユーザーが何をしたのか。今回はWebサイトの計測を想定しているが、GoogleAnalytics4はアプリの計測にも使用でき、Webサイトなのかアプリなのかでevent_nameに入る値は異なる。
以下のページにeventの一覧が載っている。
[GA4] Automatically collected events - Analytics Help

event_params.keyには、そのeventのどんな詳細情報なのかを表す文字列が入る。event_params.value.string_valueには具体的な文字列の詳細情報、event_prams.value.int_valueには整数値の情報が入る。
例えばpage_title(ページ名)やpage_location(URL)のように、文字列の値を取るような詳細情報は以下のように格納されている。

対して、ga_session_id(セッションに振られるID)など整数値を取る場合は、event_params.value.int_valueに格納される。

eventの具体例
サイト内検索結果を表すview_search_resultsを例にとって、内容を解釈する。

まずはevent_nameからユーザーがとった行動を読む。この場合はview_search_resultsとあるので検索結果を表示したということ。
event_nameのどれが何を意味するのかは上でも紹介した公式ページを参照する。
[GA4] Automatically collected events - Analytics Help

サイト内検索をした結果どのURLにユーザーがいるのか確認したい場合、event_params.keyがpage_locationの部分を見にいく。page_locationを発見したら右のevent_params.valueで具体的にどのURLかを確認する。int_valueやstring_valueなどがあるが、URLは文字列の値なのでstring_valueにのみ探している値が格納されていて、int_valueなどはNULLになっている。

検索に使用した文字列はevent_params.keyがsearch_termとなっている部分のvalueを見にいく。

ga_session_idのように整数値がはいるevent_params.keyの場合は、int_valueを見にいけば良い。
次回はセッション数をR言語で集計してみる回。
GoogleAnalytics入門 with R 前編 ~GoogleAnalyticsとは~

Webアクセス解析ツール、GoogleAnalytisの紹介。
勉強会で発表したものを文字にした記事で、元のスライドはこちら。
Introduction_of_GoogleAnalytics_with_R - Speaker Deck
記事の流れは以下の通り。
1.Webアナリストとは
2.GoogleAnalyticsとは
3.BigQuery連携データの中身
4.Rで集計してみる
前編は「GoogleAnalyticsとは」まで。
導入として基本事項を整理しただけなので、GoogleAnalyticsを普段から使っている方には不要かも。
Webアナリストとは
Webサイトのアクセスデータを中心に分析を行い、企業や組織に貢献する職種のこと。

募集要項を見るとGoogleAnalyticsや、AdobeAnalytics(「AA」と呼ばれる)の経験が求められている。他にはBIツール、SQL、Webサイトのコーディングやディレクションなど。
データ分析職の中ではビジネス寄りの立ち位置で、Webサイトの構成やWebマーケティングに対する改善施策出しが職能の軸。エンジニアリングや統計解析・機械学習の知識が求められることは少ない。ただ、後述するGoogleAnalyticsのBigQuery連携の影響でSQLの経験が求められることは増えてきそう。

GoogleAnalyticsとは

Webアナリストに求められるGoogleAnalyticsとは何かというと、Googleが提供しているWebアクセス解析サービス。Urchin(アーチン)というアクセス解析サービスの運営会社をGoogleが2005年に買収し、それを元に開発されているもの。基本無料で多くの機能を備えており、多くのWebサイトで導入されている。
以下のレポートの「アクセス解析カテゴリ内シェア」では、GoogleAnalyticsのシェアが90%を超えている(Google アナリティクスとgtagを合計)。
国内約16万Webサイトで利用されているWebサービス調査(2021年5月度) | DataSign
Webサイトに設置することで、来訪したユーザーがどこからきたのか(Google検索、Yahoo!検索、SNS、外部リンクなど)、何回訪れてきてくれているのか、使用しているデバイスは何か、など様々な情報を取得できる。
Webアナリストはこのデータを活用して、Webサイトや広告の改善施策を検討検証を行う。

GoogleAnalyticsの仕組み
Webアクセス解析ツールはデータ取得方法が複数ある。大きく分けて以下の3つ。
・タグ埋め込み型(Webビーコン型)
・サーバーログ解析型
・パケットキャプチャ型
アクセス解析ツール3つのタイプ - ログ型/ビーコン(タグ)型/パケットキャプチャ型(第2回) | アクセス解析 Step by Step | Web担当者Forum
GoogleAnalyticsはタグ埋め込み型に該当し、他の方法と比較して導入の容易さがメリット。
タグ埋め込み型におけるデータなどの流れは以下の図のようになる。

①計測タグ設置
分析者などが対象となるWebサイトに計測タグを設置する。設置されて初めて計測が始まるので過去分のデータは取得できない。計測タグ自体はJavaScriptで記述されており、GoogleAnalyticsの管理画面で発行される。設置箇所は<head>の直後が推奨されている。
②リクエスト
設置された後にユーザーからHTTPリクエストがWebサイトに送られる。
③レスポンス(+計測タグ)
Webサーバからコンテンツと共に、計測タグがユーザーのブラウザに送られてくる。
④データ送信
JavaScriptの計測タグがユーザーのブラウザ上で動作し、Web上での行動データがGoogleが持つGoogleAnalyticsサーバに送信される。
⑤集計データ
GoogleAnalyticsサーバなどで集計されたデータがGoogleAnalyticsのGUIに反映される。あくまでこれはrawデータから集計されたもの。
⑥rawデータ
後述する「BigQueryのリンク設定」を有効にすることでrawデータが自身のBigQueryに送られてくる。
次回の記事はこのBigQueryに連携されるデータについて。
R言語でSalesForceに入門する~salesforcerの紹介~

業務でSalesForceというツールを触らなければいけなくなったので入門した。
R言語を通して入門した方がわかりやすい部分もあるのかもしれないと思い、RでSalesForceを操作するパッケージ、「salesforcer」について調べたので紹介する。
そもそもSalesForceとは

SalesForceとは、CRMプラットフォームのひとつ。
CRMとは、「Customer Relationship Management」の略で、顧客と従業員の関係を管理するもの。
営業の現場でよく使われるらしく、例えば、顧客Aとは名刺交換しただけとか、顧客Bとは商談が進められているとか、顧客Cとはすでに契約が終わったとか、そういった情報を一元管理するもの。
CRMプラットフォームの中では、他のサービスと比較して、かなり広く使われている様子。
無料のデモアカウントが用意されており、登録後のトップページは以下のような感じ。
https://developer.salesforce.com/signup

salesforcerとは
このSalesForceをR言語を使って操作していく。それを簡単にできるのが「salesforcer」というパッケージ。以下で使用方法を見ていく。

まずは認証情報を設定してSalesForceに接続。
ユーザー名、パスワード、セキュリティトークンを引数に渡すと接続できる。
セキュリティトークンは、個人設定から「私のセキュリティトークンのリセット」を選択すると登録してあるメールアドレスに送られてくる。アカウントにIP制限がかかっていると、個人設定に「私のセキュリティトークンのリセット」という項目が出てこないので、制限を一時的に解除する必要がある。

オブジェクトとは
「オブジェクト」とは、SalesForceの用語でテーブルのようなもの。GUIの上の方に並んでいるタブのひとつひとつがオブジェクト。

表示されているものは全てではない。sf_list_objects()でオブジェクトのメタデータを取得できるので、そこからオブジェクト一覧を抽出して確認できる。デフォルトで663個もあるらしい。

SOQLとは
SOQLという用語もあり、これはSQLのSalesForce版。
ちなみにSQLは正式には何かの略語ではないらしい。知らなかった。
文字列でクエリを書いてsf_query()という関数に渡すと実行される。FROMにはオブジェクトを指定する。

レポートとは
他のオブジェクトから集計したものをレポートと呼ぶ。
sf_create_report()という関数で作成する。nameという引数にレポート名、report_typeという引数には、「レポートタイプ」を指定する。レポートタイプはsf_list_report_types()で取得できる。
GUI上だと、集計したりできるようだが、salesforcerではあまり自由が効かないのか、フィルターをかけるくらいしかできない?そんな訳ない気がするので要調査。フィルターはlist形式で作成して、sf_run_report()のreport_filtersという引数に渡すと適用されたレポートが作成される。

終わり
レポートを自由に作れると便利かもと思ったけど、そんなに自由に動くわけではなさそうかも。
データの取得は簡単にできるので、R言語でなんやかんやして、どこか別の場所に結果を返すのはできそう。
初見でGUI操作のチュートリアルに入るよりも、R言語通した方が分かりやすかった感覚はあるので、BIツールの入門方法としてありかもしれない。
全スライドは以下に置いてあり、本記事のR言語でやったことをGUIでやる場合はどうするのかも紹介している。
start-salesforce-with-r - Speaker Deck
参考文献
・Qiita, 「エンジニアのためのsalesforce超入門」
https://qiita.com/tarokamikaze/items/0bc2988534f63d4b65c5
ER図とかも描いてあるQiitaの入門記事。エンジニアは大変らしい。
・TRAILHEAD
https://trailhead.salesforce.com/ja/home
公式が用意しているチュートリアル。かなり量があるので必要なところを。
・GitHub, 「An Implementation of Salesforce APIs Using Tidy Principles • salesforcer」
https://stevenmmortimer.github.io/salesforcer/index.html
・CRAN, 「Package salesforcer」
https://cloud.r-project.org/web/packages/salesforcer/index.html

feature_fractionが変数重要度に与える影響
LightGBMのfeature_fractionは重要度に影響与えるよ〜という話を聞いたので実験。テストデータはkaggleのHousePricesをお借りする。
feature_fractionとは
・LightGBM will randomly select part of features on each iteration (tree) if feature_fraction smaller than 1.0. For example, if you set it to 0.8, LightGBM will select 80% of features before training each tree
・can be used to speed up training
・can be used to deal with over-fitting
https://lightgbm.readthedocs.io/en/latest/Parameters.html
ということで、木ごとに特徴量のサンプリングを行うもの。学習速度向上と過学習の抑制に効果がある。
実験
HousePricesを使ってfeature_fractionを1.0、0.5、0.1と変えた時に変数重要度がどうなるのか実験してみる。validationは5foldsのCrossValidation。feature_fractionのrandom_seedをそれぞれ10種類試して、重要度の平均をとって比較する。重要度のタイプはgain。
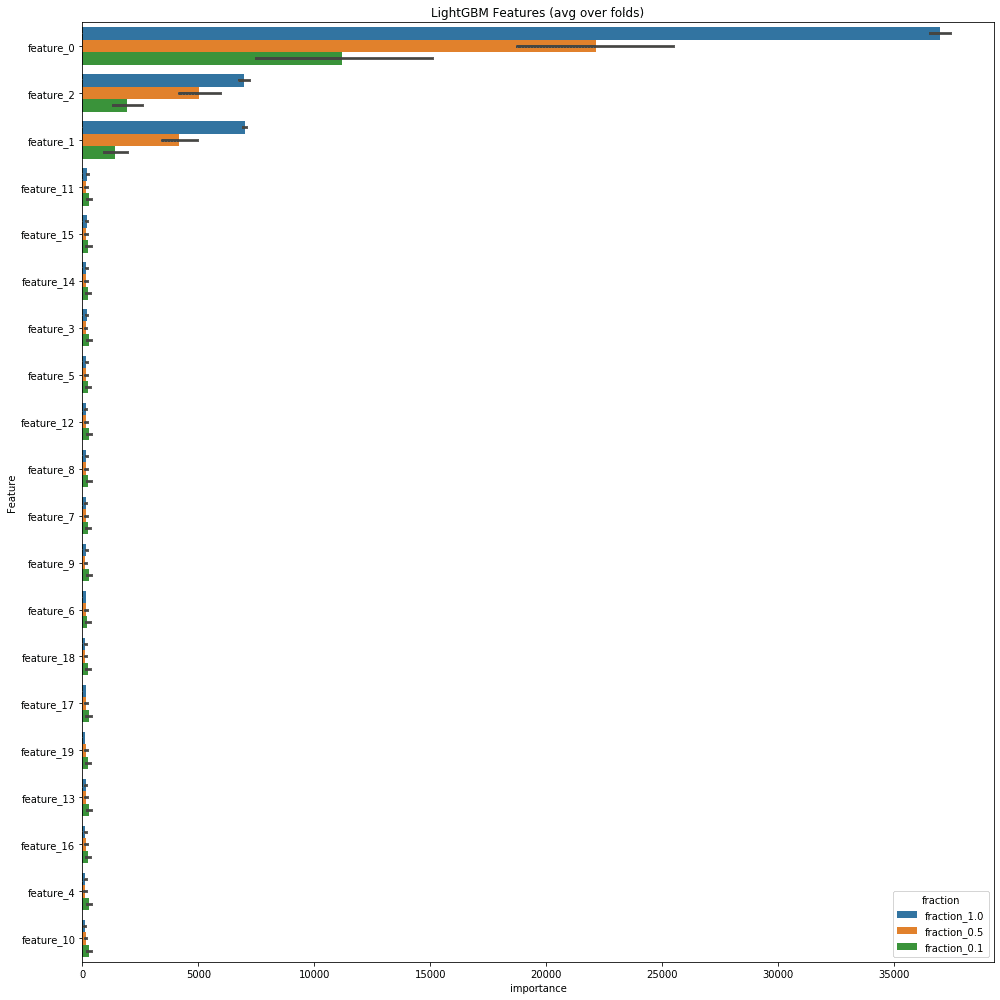
以下がその結果の変数重要度。全体をベタっと貼る。
青色がfeature_fraction1.0、橙色が0.5、緑色が0.1。

重要度の高いものを見ると特に重要度の高かったOverallQualがfeature_fractionが小さく設定されるにつれ、そのfeature_fraction内での重要度が相対的に低くなっている。
下位の特徴量ではfeature_fraction1.0の場合は急激に下がっていくのに対して、0.1ではあまり下がらずより広い範囲に重要度が散らばっている。
同じデータ、同じvalidationの切り方、同じモデルでもかなり印象が異なる。
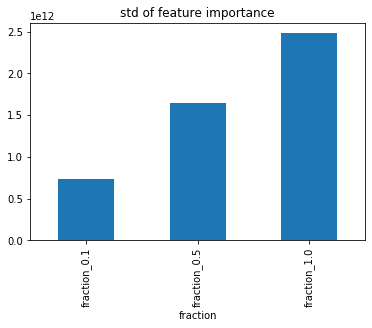
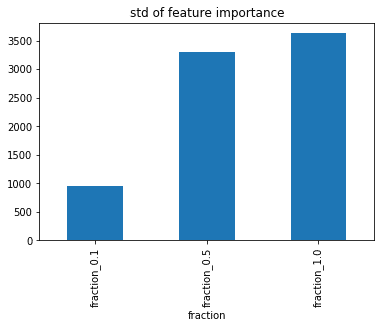
各feature_fractionで重要度の標準偏差を集計してみると、feature_fractionが高いほど標準偏差が大きい。
人口データで実験
sklearnのmake_classifitacionを使用して生成したデータでも実験。サンプルサイズ10,000、特徴量20個、意味のある特徴量の数(n_informative)は3個、クラスごとのクラスターの数(n_clusters_per_class)は1。
make_classificationは前にkaggleで使用されたことがあった。
https://www.kaggle.com/cdeotte/3-clusters-per-class-0-975
https://www.kaggle.com/c/instant-gratification/discussion/96519
CVの方法などは全てHousePricesと同じ条件で実験。
結果は以下の通り。
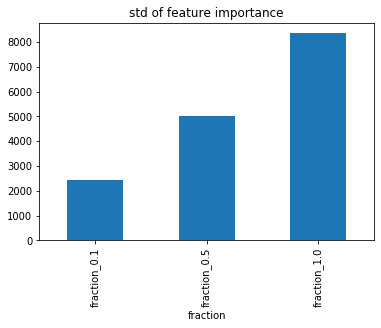
傾向としては同じ様子。feature_fractionが小さくなるほど重要度が全体にばらける。
クラスごとのクラスターの数(n_clusters_per_class)を3に変えてみる。それ以外は全て同じ。
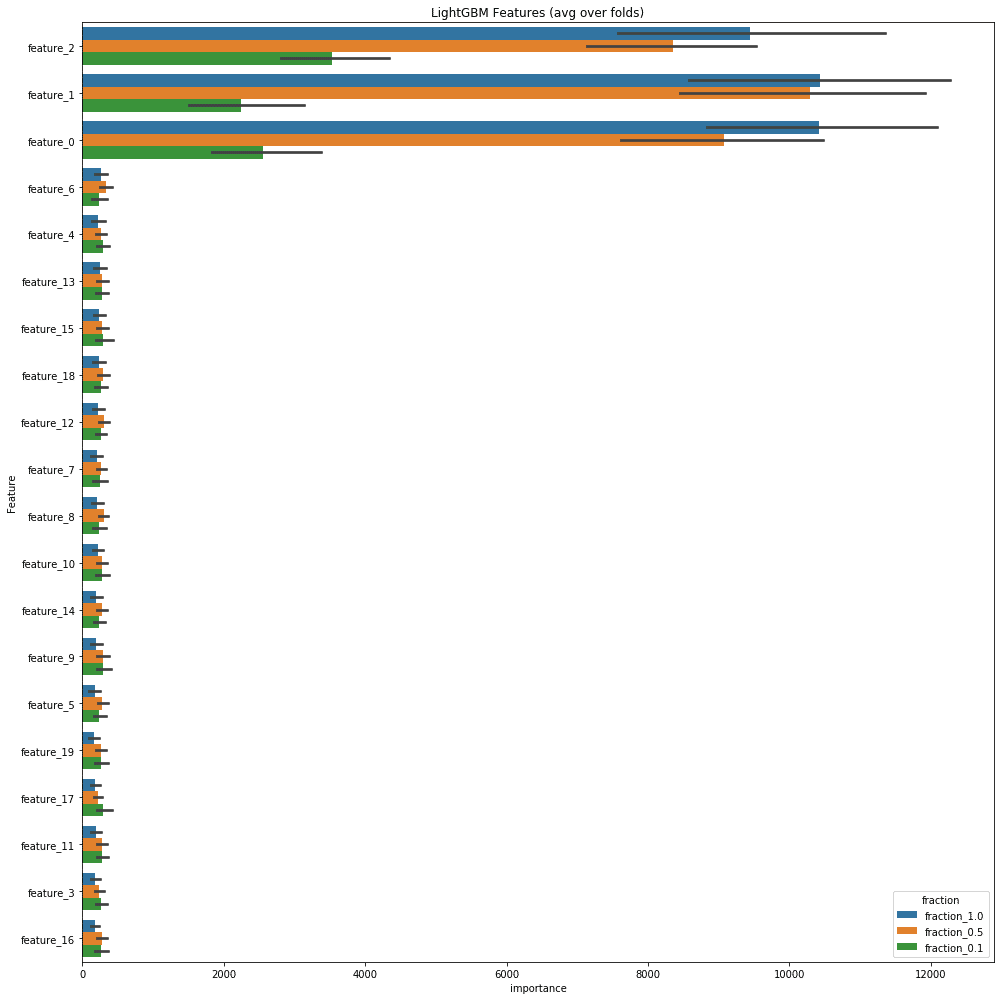
だいぶ印象が変わったぞ??標準偏差で見ればばらつきが小さくなっていくのは変わらないものの、1.0と0.5であまり変わらなくなっている。
なぜfeature_fractionが重要度に影響するのか?
HousePricesで言うと目的変数であるSalePriceを予測するのにOverallQualがめちゃくちゃ効くけど、feature_fractionの結果、ある木ではOverallQualが特徴量として使われていないため他の特徴量でなんとか学習するしかなく、全特徴量を使った時には比較的重要度の低かった特徴量にも重要度が振られるようになる、ということらしい。今回は試せていないけどborutaやらnull importanceやらにしたらまた結果が変わるかもしれない。
この辺のことちゃんと書いてあるのあったら教えてください。
終わり
重要度を解釈する時にfeature_fractionの値によって、重要度に影響が出る。解釈する時にはそのことを考慮しながら行う。もしくは重要度の解釈時のみ1.0にしておくとかだろうか。
"polite"で守るWebスクレイピングのエチケット

Webスクレイピングの際には法律的なものなど、注意しなければならない点がいくつもあるが、それらの一部をサポートするR言語のパッケージ『polite』の紹介をする。
2020年12月5日に開催されたR言語の勉強会、「Japan.R」で発表した内容を掲載。
Webスクレイピングとは
Webスクレイピングとは、Webサイトから情報を抽出してくるコンピュータソフトウェア技術のこと。手作業でコピーアンドペーストしてもWebスクレイピングと呼ばれるという話もみたことがある。
便利な技術ではあるものの、法律など気をつけなければならない点が多数存在する。
以下はそのうちの一部。

politeパッケージとは
RDocumentationには「責任あるWebエチケットの推進」が目的であるとされているR言語のパッケージ。
このpoliteによるセッションには以下の3つの柱があると記載されている。

それぞれ雑に翻訳すると「取得許可の確認」「取得感覚を空ける」「確認を繰り返さない」と言える、と思う。これら基本的なスクレイピングのエチケットの遵守を、politeパッケージはサポートしてくれる。
ただし、個人情報保護、Webサイトの利用規約、著作権の問題など、politeを通してスクレイピングするだけでは解決できない問題もあるので、その点は別途注意しなければいけない。
politeパッケージの使用手順
ざっくり以下の4つ(3つ)のステップに分かれる。3番目のrvestはpoliteとは別のパッケージなので「4つ(3つ)」。

1,bow
ホストに対して自己紹介をする関数。
主な引数はurl、user_agent、delayの3つ。
UserAgentとはウェブサイトにアクセスするユーザーのOSやブラウザの情報などをまとめたもの。関数を実行することで、ホストにこれを送信する。これに加えて、自身の連絡先を載せておくと、何か問題があった際にホストが連絡を取りやすいのでより良い。
delayはスクレイピングの間隔を指定する。デフォルトだと5秒。あまり短い間隔でリクエストを送ってしまうと、相手側のサーバに高い負荷を掛けてしまうことになるので、適切な秒数を設定する。(1秒としている場合が多いようだが、適切な秒数が明確に示されている訳ではない???)
この取得間隔の設定が、RDocumentationにあった3本柱の1つ、「taking slowly」の実践となる。

session <- polite::bow(url = "https://www.cheese.com/by_type",
user_agent = "UAと連絡先の文字列を記載",
delay = 5)
また、bowでは指定したパスを取得して良いのか確認を行なっている。この許可は「robots.txt」というクローラーへの取得許可不許可を記載しているテキストファイルを確認しており、これが3本柱の2つ目、「seeking permission」の実践。

ちなみに、許可されていない場合は以下のように警告文が表示される。

2,scrape
実際に対象ページを取得してくる関数。
前のステップで作成したbowオブジェクトを渡すbowと、URLに追加するパラメータを指定するqueryが主な引数。
queryは以下の赤枠にあるように、list形式で渡し、それがbowで指定したパスにパラメータとして追加される。

scr_obj <- polite::scrape(bow = session,
query = list(t = "semi-soft", per_page = 100))
3,rvest
R言語でのスクレイピングで使用されるパッケージ。scrapeで取得したHTML Documentから必要な情報を抽出する。
使用方法などは以下の画像にある参考文献を参照。

result <- scr_obj %>%
rvest::html_node(css = "#main-body") %>%
rvest::html_nodes(css = "h3") %>%
rvest::html_text()
4,nod
nodは取得先のパスを変更する場合に使用する関数。
bowのurlを変更すれば、それでも良いが、ホストに対してUserAgentを繰り返し送信してしまうことになり、robots.txtもすでに取得しているので、それらを繰り返さない為にこちらを使用する。これが3本柱の最後の1つ、「never asking twice」。
主な引数はbowオブジェクトを渡すbowと、変更先のパスを指定するpath。

nod_obj <- polite::nod(bow = session,
path = "https://www.cheese.com/by_country")
まとめ
politeの手順と、politeの3本柱は以下の通り。

その他注意事項
以下のように、利用規約、個人情報、著作権など、注意しなければいけない点は多い。
スクレイピングや機械学習周りの法律専門の会社もあるので、頼ってみるのも手。

参考文献
Octoparse, 「Webスクレイピングとは?定義から応用までの説明」
https://www.octoparse.jp/blog/web-scraping/
PigData, IT弁護士に聞く「企業としてのスクレイピングは違法なのか?」
https://services.sms-datatech.co.jp/pig-data/2019/07/03/scrapinglaw/
R Documentation, 「polite package」
https://www.rdocumentation.org/packages/polite/versions/0.1.1
R Documentation, 「rvest package」
https://www.rdocumentation.org/packages/rvest/versions/0.3.6
アクセス解析ツール「AIアナリスト」ブログ,
「robots.txtとは?意味から設定方法まで詳しく解説」
https://wacul-ai.com/blog/seo/internal-seo/seo-robots-txt/
R Documentation, 「robotstxt package」
https://www.rdocumentation.org/packages/robotstxt/versions/0.7.13
文化庁, 「著作物が自由に使える場合」
https://www.bunka.go.jp/seisaku/chosakuken/seidokaisetsu/gaiyo/chosakubutsu_jiyu.html
Stimulator, 「Webスクレイピングする際のルールとPythonによる規約の読み込み」
https://vaaaaaanquish.hatenablog.com/entry/2017/12/01/064227
IT法務・AI・Fintechの法律に詳しい弁護士|中野秀俊, 「【スクレイピングと法律】スクレイピングって法律的に何がOKで何がOUTなのかを弁護士が解説。」
https://it-bengosi.com/blog/scraping/
PigData, 「【スクレイピング】違法にならないサービスパターン5選」
https://services.sms-datatech.co.jp/pig-data/2020/01/15/scrapinglaw3/
「Intro to {polite} Web Scraping of Soccer Data with R!」
https://ryo-n7.github.io/2020-05-14-webscrape-soccer-data-with-R/
石田 基広, 市川 太祐, 瓜生 真也, 湯谷 啓明, シーアンドアール研究所,「Rによるスクレイピング入門」
https://www.amazon.co.jp/dp/486354216X
松村 優哉, 湯谷 啓明, 前田 和寛, 紀ノ定 保礼, 技術評論社,
「RユーザのためのRStudio[実践]入門−tidyverseによるモダンな分析フローの世界−」
https://www.amazon.co.jp/dp/4774198536
終わり

スライドはこちら。
https://speakerdeck.com/bk_18/web-scraping-with-polite-package