feature_fractionが変数重要度に与える影響
LightGBMのfeature_fractionは重要度に影響与えるよ〜という話を聞いたので実験。テストデータはkaggleのHousePricesをお借りする。
feature_fractionとは
・LightGBM will randomly select part of features on each iteration (tree) if feature_fraction smaller than 1.0. For example, if you set it to 0.8, LightGBM will select 80% of features before training each tree
・can be used to speed up training
・can be used to deal with over-fitting
https://lightgbm.readthedocs.io/en/latest/Parameters.html
ということで、木ごとに特徴量のサンプリングを行うもの。学習速度向上と過学習の抑制に効果がある。
実験
HousePricesを使ってfeature_fractionを1.0、0.5、0.1と変えた時に変数重要度がどうなるのか実験してみる。validationは5foldsのCrossValidation。feature_fractionのrandom_seedをそれぞれ10種類試して、重要度の平均をとって比較する。重要度のタイプはgain。
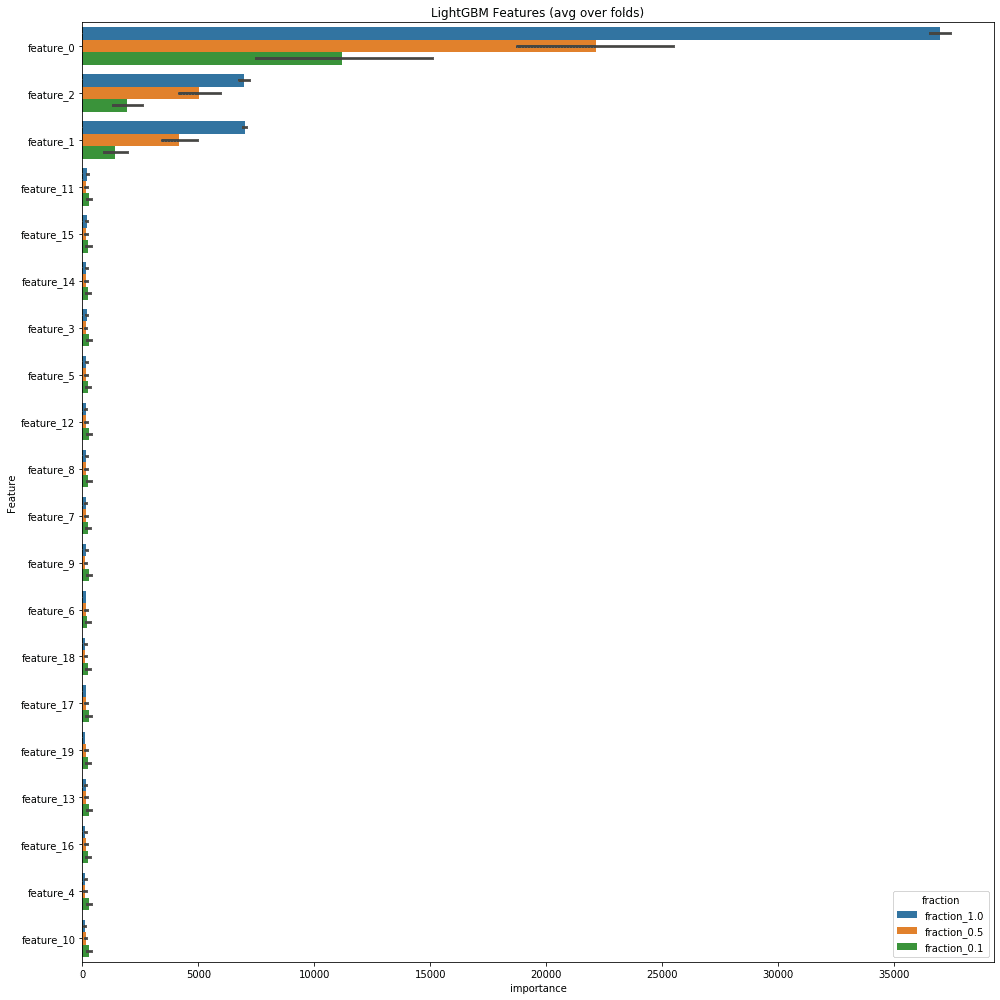
以下がその結果の変数重要度。全体をベタっと貼る。
青色がfeature_fraction1.0、橙色が0.5、緑色が0.1。

重要度の高いものを見ると特に重要度の高かったOverallQualがfeature_fractionが小さく設定されるにつれ、そのfeature_fraction内での重要度が相対的に低くなっている。
下位の特徴量ではfeature_fraction1.0の場合は急激に下がっていくのに対して、0.1ではあまり下がらずより広い範囲に重要度が散らばっている。
同じデータ、同じvalidationの切り方、同じモデルでもかなり印象が異なる。
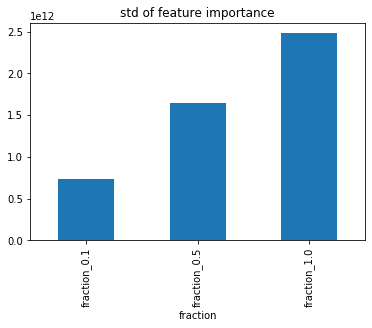
各feature_fractionで重要度の標準偏差を集計してみると、feature_fractionが高いほど標準偏差が大きい。
人口データで実験
sklearnのmake_classifitacionを使用して生成したデータでも実験。サンプルサイズ10,000、特徴量20個、意味のある特徴量の数(n_informative)は3個、クラスごとのクラスターの数(n_clusters_per_class)は1。
make_classificationは前にkaggleで使用されたことがあった。
https://www.kaggle.com/cdeotte/3-clusters-per-class-0-975
https://www.kaggle.com/c/instant-gratification/discussion/96519
CVの方法などは全てHousePricesと同じ条件で実験。
結果は以下の通り。
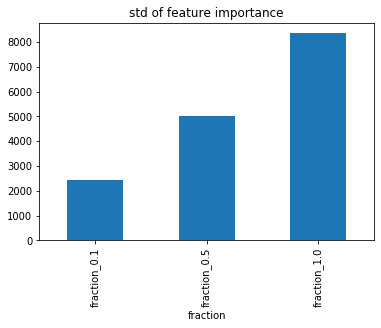
傾向としては同じ様子。feature_fractionが小さくなるほど重要度が全体にばらける。
クラスごとのクラスターの数(n_clusters_per_class)を3に変えてみる。それ以外は全て同じ。
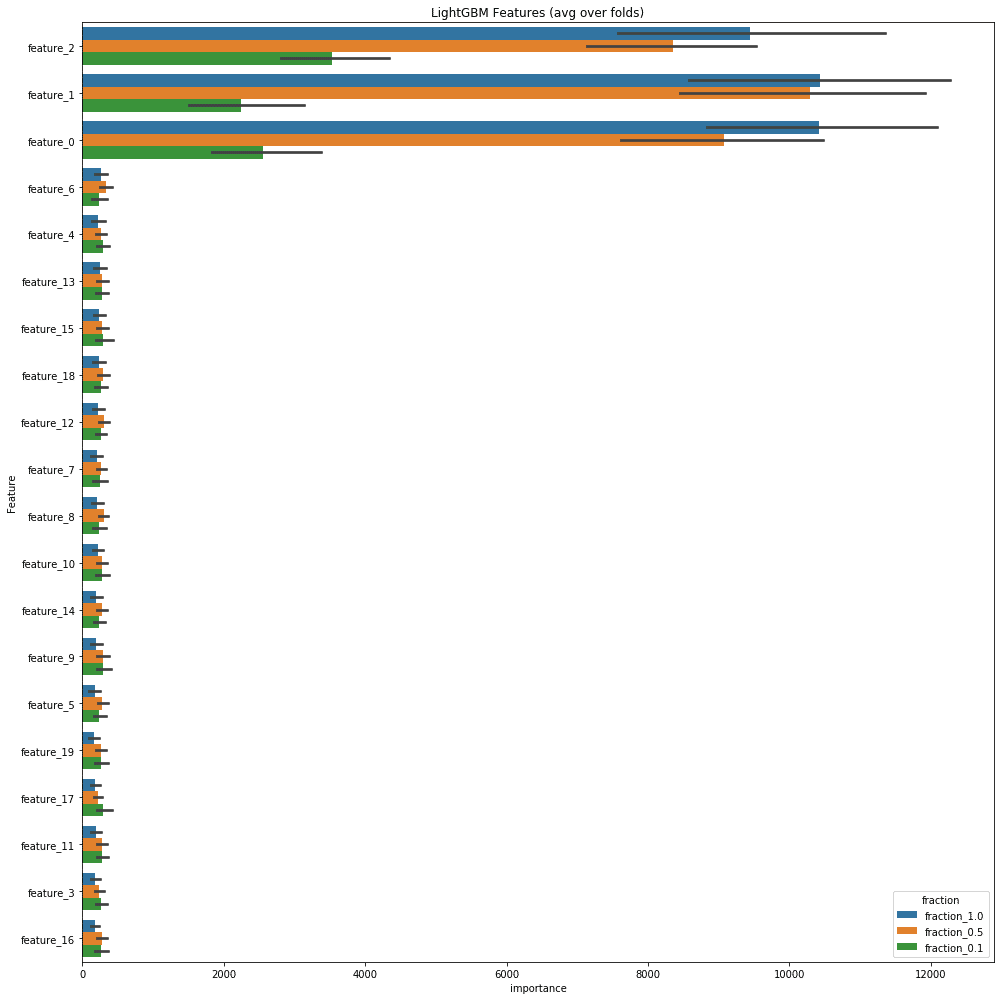
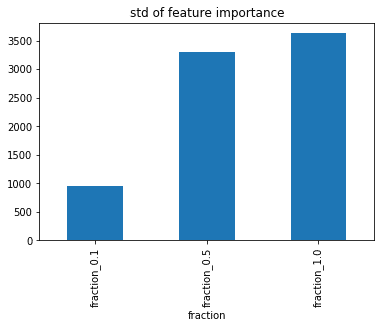
だいぶ印象が変わったぞ??標準偏差で見ればばらつきが小さくなっていくのは変わらないものの、1.0と0.5であまり変わらなくなっている。
なぜfeature_fractionが重要度に影響するのか?
HousePricesで言うと目的変数であるSalePriceを予測するのにOverallQualがめちゃくちゃ効くけど、feature_fractionの結果、ある木ではOverallQualが特徴量として使われていないため他の特徴量でなんとか学習するしかなく、全特徴量を使った時には比較的重要度の低かった特徴量にも重要度が振られるようになる、ということらしい。今回は試せていないけどborutaやらnull importanceやらにしたらまた結果が変わるかもしれない。
この辺のことちゃんと書いてあるのあったら教えてください。
終わり
重要度を解釈する時にfeature_fractionの値によって、重要度に影響が出る。解釈する時にはそのことを考慮しながら行う。もしくは重要度の解釈時のみ1.0にしておくとかだろうか。